
VÝBĚR Z OBLASTI
Uživatelské rozhraní
DAD
flexideo tools
Systém aktualizací
Ke stažení
Doplňování csv dat - postup
Pokud je třeba dodanou externí tabulku doplnit snadno a rychle dle párovacího kódu údaji ze systému flexideo, je možné s výhodou použít nástroj pro doplňování do CSV tabulek. Nástroj umožňuje přímo do csv dat přidat do sloupců určených pomocí hodnot xds-id v hlavičkách dohledané (připárované) hodnoty. V jednom csv souboru je možno doplňovat pouze data jednoho typu dokumentu dle nastavení úlohy. Klíčové sloupce v souboru musí být označeny 8-mi místnými číselnými kódy kolonek. To, podle čeho mají být údaje dohledány a které hodnoty a kam ma jí být z databáze zařazeny pozná algoritmus nástroje z osmimístného identifikačního čísla kolonky, které je v celé databázi jedinečné. Vzhledem k tomu, že je možné doplňovat do jedné tabulky data pouze z jediného typu dokumentu, má program reálnou šanci kontrolovat i správnost zadání těchto identifikátorů. Identifikátory jednotlivých kolonek je vedle prohlížeče kompletní struktury XDS možné též získat přímo z intranetového rozhraní z formuláře dokumentu požadovaného typu - vyskytuje se v rámci popisu jednotlivých kolonek, který je automaticky po výběru kolonky zobrazován ve spodní části formuláře v hranaté závorce jako [id: ...]. Kód kolonky naleznete rovněž v menu u každé kolonky, odkud je možné jej i kopírovat. Tato čísla jsou do souboru zapisována tak jak ukazuje následující příklad:
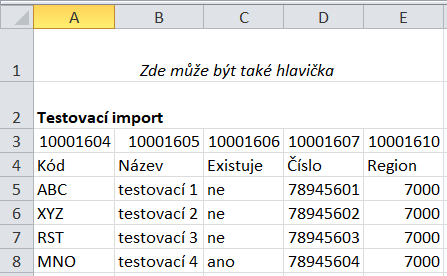
Je-li v souboru hlavička sloupců, pak tyto identifikátory musí ležet hned v řádku nad touto hlavičkou. Pokud v souboru není (a v nastaveních úlohy je hlavička vypnuta), pak číselné identifikátory leží přímo nad prvním řádkem s daty. Vyskytují-li se pak řádky prázdné, doplňovací nástroj je vynechá (i kdekoli později v seznamu, jsou-li prázdné jako celek). Rovněž tak vynechává řádky nad těmito číselnými identifikátory. Sloupce, které jsou kódem označeny pro doplnění (na obrázku jsou prázdné, ale není to nutné) budou po proběhnutí úlohy doplněny údaji a soubor bude uložen pod svůj původní název a přepíše tak ten původní. Pro správnou funkci doplnění je třeba nastavit správně použitou úlohu:
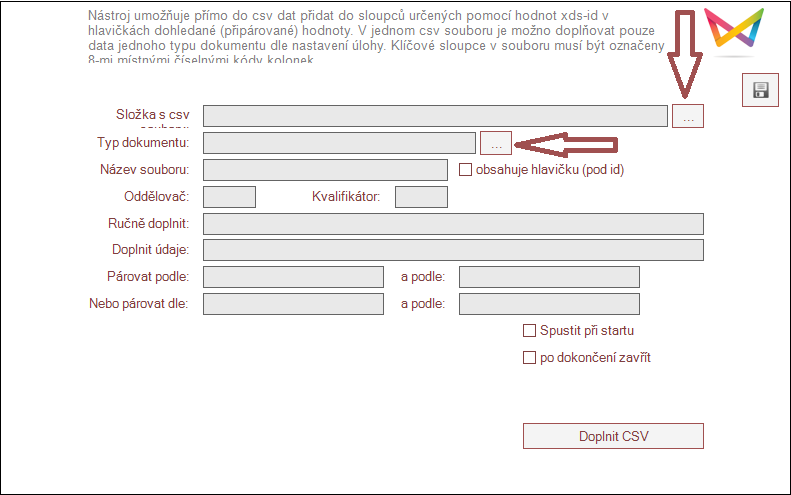
Vedle vstupní složky, která je povinným údajem udávajícím úložiště csv souborů je rovněž třeba přesně zadat konkrétní typ dokumentu dle typů dokumentů, které se v databázi aplikace vyskytují, a ze kterého mají být data doplněna. V nastavení názvu souboru je pak zapotřebí zadat buď konkrétní jméno csv souboru nebo pomocí masky (hvězdičkové konvence) přednastavit souborový filtr. Důležitým, ale nikoli povinným údajem je kolonka oddělovač, kam je možno zadat vlastní znak nebo sekvenci znaků. Není-li oddělovač zadán, je použito výchozího středníku (;). Další důležitou volbou je nastavení s názvem "obsahuje hlavičku (pod id)", které algoritmu říká, zda má počítat s jedním řádkem s názvy sloupců hned pod řádkem s číselnými identifikátory hodnot.
Dlouhá kolonka s názvem Ručně doplnit umožňuje přikládání fixních hodnot ke všem doplňovaným řádkům, pokud se mají pro určitý účel opakovat. Hodnoty se však stejně dobře dají použít v odkazu jako pomocné párovací tak, jak je to i na obrázku s příkladem nastavení úlohy. Jde o čárkami oddělený seznam xds identifikátorů, kterými jsou stejná 8-místná čísla, jako ty umisťované nad sloupce v importovaných tabulkách. Ke každému kódu bude při importu vznesen doplňovacím algoritmem dotaz na zadání jednotné hodnoty uživatelem pro všechny doplňované soubory a jejich řádky. Dotaz bude automaticky doplněn o název získaný ze souboru struktury z webového sídla systému a bude též doplněn obecnou validací (např. neumožní do číselné kolonky zadat text a vyžádá si platné zadání).
Kolonka doplnit údaje pak úloze říká, které údaje ze systému mají být doplněny. Jde opět o čárkami oddělený seznam 8-místných identifikátorů kolonek, které je zároveň třeba doplnit i do hlaviček cílových sloupců v doplňovaném souboru tak, jak je naznačeno v příkladu korespondujícím s obrázkem nastavení úlohy.
Významná jsou pro doplnění samozřejmě i nastavení párovacích údajů, kde jsou v nastavení úlohy k dispozici 4 kolonky pro zadání vždy jednoho párovacího 8-místného identifikátoru. Identifikátor zde určuje údaj, podle kterého se má provést vyhledání hodnoty v systému pro doplnění na jednotlivé řádky souboru. Takto identifikované hodnoty se samozřejmě pak musejí vyskytovat buď přímo v souboru nebo v předchozí kolonce uživatelem ručně zadávaných údajů. Jinou možností je hodnotu zadat přímo do kolonky formou např. 10001234=ahoj. Pak bude podmínkou, že se při párování v určité logické souvislosti budou brát v úvahu záznamy, kde je v prvku 10001234 hodnota 'ahoj'. Zmíněné čtyři kolonky mají mezi sebou následující logický vztah:
(A AND B) OR (C AND D)Tento vzthah platí pokud jsou všechny vyplněny. Většinou však je uváděna jedna nebo dvě kolonky a pak se logický vztah upravuje např. takto:
A AND Bnebo
A OR Cpříp.
(A AND B) OR CVždy však jde o to, že hodnota v souboru či nastavení se rovná hodnotě uložené v databázi. Pokud dojde k nalezení odpovídajícího údaje, je záznam v databázi použit pro kopii hodnoty do souboru.
Volba spustit při startu umožní při aktivaci nástroje (např. zástupcem přímo ze složky, kde je vstupní soubor umístěn) rovnou úlohu spustit bez dalšího klikání. Obdobnou volbu je možné najít u nástroje pro vkládání příloh a csv importu. Poslední zatrhávací pole umožňuje automaticky okno nástrojů po dokončení úlohy zavřít, což vede k vyšší pracovní efektivitě v běžné praxi.
Tak jak je v nástojích obvyklé, je možné předdefinovat uživatelům několik běžných úloh otevíraných vhodně připravenými zástupci přímo z pracovních složek na straně jedné (viz. Pracovní složky a nastavení) a šablon doplňovaných tabulek pro Excel či jiný tabulkový kalkulátor na straně druhé a zajistit tak snadné doplňování externích tabulkových dat.