
VÝBĚR Z OBLASTI
Uživatelské rozhraní
DAD
flexideo tools
Systém aktualizací
Ke stažení
Import csv dat - postup
Častým požadavkem na práci s daty bývá jejich snadné pořizování z externích zdrojů. Systém flexideo disponuje vedle běžných formulářů dokumentů pro přímé zadávání dat také hned několika možnostmi importu, kde každá má trochu jiný charakter. Pro větší objemy dat a při zakládání databází je vzhodný tzv. force import, pro běžné importování dat je pak možné využívat přehledů pro namapování importů dle těchto přehledů. Jinou možností je automatizovat složité výměny dat pomocí XML mapování na externí aplikace nebo využití možností XML protokolu pro ukládání dat přímo. Nástroj Import csv dat využívá posledně zmíněného protokolu a popisu struktury dokumentu dostupného na webovém sídle k tomu, aby data jednak ověřil z hlediska jejich základního datového formátu a jednak je zařadil tam, kam patří. Tento nástroj, jak název napovídá, slouží k načítání csv (Comma Separated Values) textových tabulek. To, kam který sloupec v databázi patří pozná algoritmus nástroje z osmimístného identifikačního čísla kolonky, které je v celé databázi jedinečné. Vzhledem k tomu, že je možné importovat pouze data jediného typu dokumentu, má program reálnou šanci kontrolovat i správnost zadání těchto identifikátorů. Identifikátory jednotlivých kolonek je vedle prohlížeče kompletní struktury XDS možné též získat přímo z intranetového rozhraní z formuláře dokumentu požadovaného typu - vyskytuje se v rámci popisu jednotlivých kolonek, který je automaticky po výběru kolonky zobrazován ve spodní části formuláře v hranaté závorce jako [id: ...]. Kód kolonky naleznete rovněž v menu u každé kolonky, odkud je možné jej i kopírovat. Tato čísla jsou do souboru zapisována tak jak ukazuje následující příklad:
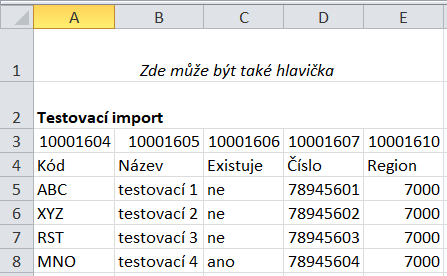
Je-li v souboru hlavička sloupců, pak tyto identifikátory musí ležet hned v řádku nad touto hlavičkou. Pokud v souboru není (a v nastaveních úlohy je hlavička vypnuta), pak číselné identifikátory leží přímo nad prvním řádkem s daty. Vyskytují-li se pak řádky prázdné, importní nástroj je vynechá (i kdekoli později v seznamu, jsou-li prázdné jako celek). Rovněž tak vynechává řádky nad těmito číselnými identifikátory. Pokud uvedete dva stejné identifikátory u dvou či více sloupců dojde ke sloučení hodnot do společné cílové kolonky. Po úspěšném importu je vstupní csv soubor ze složky mazán. Importní nástroj nabízí celou řadu nastavení, jak ukazuje náhled na nastavení úlohy importu:

Vedle vstupní složky (zde můžete využít tzv. selektoru jako u vyběru typu dokumentů), která je povinným údajem udávajícím úložiště csv souborů je rovněž třeba přesně zadat konkrétní typ dokumentu dle typů dokumentů, které se v databázi aplikace vyskytují, a do kterého mají být data importována. Dále ve výběru typu dokumentů máte možnost využít tzv. selektoru kde vyberete daný typ dokumentu. viz.Import CSV dat V nastavení názvu souboru je pak zapotřebí zadat buď konkrétní jméno csv souboru nebo pomocí masky (hvězdičkové konvence) přednastavit souborový filtr. Chcete-li jméno zdrojového souboru položky následně dohledat v jednotlivých záznamech v poznámce, zatrhněte volbu Jm. souboru do poznámky a nebo v nadpisu dokumentu, zatrhněte volbu Jm. souboru do štítku. Do štítku se název vkládá bez doprovodného textu a bez přípony souboru za tečkou. Je možná i kombinace obojího. Důležitým, ale nikoli povinným údajem je kolonka oddělovač, kam je možno zadat vlastní znak nebo sekvenci znaků. Není-li oddělovač zadán, je použito výchozího středníku (;). Důležitou volbou je nastavení s názvem "obsahuje hlavičku (pod id)", které algoritmu říká, zda má počítat s jedním řádkem s názvy sloupců hned pod řádkem s číselnými identifikátory hodnot. Hlavička s názvy sloupců může najít dobré uplatnění i v kombinaci s volbou "Neoznačené do poznámky", která zajistí, že budou importovány i sloupce bez označení identifikátorem struktury (ten opravdu u všech sloupců být nemusí), ale vloží se do poznámky každé importované instance i spolu s názvem sloupce údaje ve formě hlavička: hodnota;. Užitečnou může být i volba "ochránit cizí pole, která zamezí zapisu hodnot do polí se zdrojovým mechanismem typu foreign, který způsobí vytvoření zdrojové instance na pozadí ukládání každé instance importovaného typu. Další volbou v nastavení importní úlohy je volba s názvem "vypínat výpočty", jež zajistí vypnutí automatického přepočtu kolonky ve formuláři, pokud kolonka výpočet obsahuje a zajistí tak zachování importované hodnoty. Někdy je však zachování automatického přepočtu důležitější a pak se volba nezatrhává.
Dlouhá kolonka s názvem Ručně doplnit umožňuje přikládání fixních hodnot ke všem importovaným řádkům, pokud se mají pro určitý účel importu opakovat. Jde o čárkami oddělený seznam xds identifikátorů, kterými jsou stejná 8-místná čísla, jako ty umisťované nad sloupce v importovaných tabulkách. Ke každému kódu bude při importu vznesen importním algoritmem dotaz uživateli na zadání jednotné hodnoty pro všechny importované soubory a jejich řádky. Dotaz v dialogu bude automaticky doplněn o název získaný ze souboru struktury z webového sídla systému a bude též doplněn obecnou validací (např. neumožní do číselné kolonky zadat text a vyžádá si platné zadání). Kolonka dále umožňuje naplňovat při importu výchozí hodnotou dle nastavení nebo přímo do kolonky vložit konstantní zadání. Aby byly tyto stavy odlišeny, je třeba použít znakového prefixu. Úplná syntaxe kolonky je následující:
[d:|i:|v:]{#xds-id}[={#value}][-{formatTempName}]Prefix d: (dialog) není třeba uvádět, je předpokládán. Prefix i: (initial), tedy definovaná výchozí hodnota zajistí, že v rámci importního souboru bude tato výchozí hodnota nastavována. Má to význam např. při importech s párováním, kdy je takto možné nastavovat výchozí hodnotu nebo při využití formátovací šablony. Jinak obecně platí, že není-li pro nový záznam explicitně dána určitá hodnota, použije se pro zápis hodnota výchozí daná definicí (více viz. vlastnost initial v XDS). Posledním prefixem je v:, který umožňuje přímo do kolonky zapsat určitou hodnotu. Zadání je však velmi omezené. Je možné buď zadávat číselné hodnoty nebo alfanumerické řetězce bez mezer a dalších oddělovačů (jediné povolená jsou podtržítka). Je tedy využitelné především pro zadávání různých kódů do spec. kolonek nebo k naplňování logických a číselných typů.
Příklady možného zadání:
10002345d:10002345i:10002345i:10002345-myTemplatev:10002345=muj_kodi:10002345-zapsat(muj_kod)
Tyto zápisy je rovněž možné zapsat najednou (samozřejmě se správnými id) a oddělit je čárkami. První a druhý mají totožný dopad - zobrazí dialog s možností zadat údaj pro identifikovanou kolonku. Třetí jen nastavuje do importu výchozí hodnotu (u přidávání nových záznamů nemá význam). Ve čtvrtém je totéž, ale je využita XSL pojmenovaná šablona. Tyto šablony se nacházejí v souoru šablon, jenž je možné najít v podsložce a souboru csv-import\temps\formats.xsl pracovní složky nástrojů. Název za pomlčkou je pak názvem určité XSL šablony pro úpravu hodnoty. Pátý příklad ukazuje, jak je možné v importu určitou kolonku naplnit konstantní hodnotou u všech importovaných záznamů. Totéž dělá i šestý příklad za předpokladu, že existuje šablona zapsat, která přebírá parametr v závorce. Do šablony se hodnota ze závorek ve výrazu předává pomocí atributu f-params. Šablona zapsat v souboru formats.xsl by pak vypadala jednoduše takto:
<xsl:template name="zapsat"><xsl:value-of select="@f-params"/></xsl:template>
Jako další jsou v nastavení importního nástroje k dispozici 4 kolonky pro zadání vždy jednoho párovacího identifikátoru. Jde opět o 8-místné xds-id určující údaj, podle kterého se mají importované řádky párovat na již existující záznamy (dokumenty) v datábázi systému. Takto identifikované hodnoty se samozřejmě pak musejí vyskytovat buď přímo v souboru nebo v předchozí kolonce uživatelem ručně zadávaných údajů. Jinou možností je hodnotu zadat přímo do kolonky formou např. 10001234=ahoj. Pak bude podmínkou, že se při párování v určité logické souvislosti budou brát v úvahu záznamy, kde je v prvku 10001234 hodnota 'ahoj'. Pro párování je možné použít i primárních klíčů dokumentů (pdk), pokud je znáte. Pro tento účel je možné do párovací kolonky uvést id celého typu dokumentu, který je importován, primární klíč je jím pro tyto účely identifikován.
Zmíněné čtyři párovací kolonky mají mezi sebou následující logický vztah:
(A AND B) OR (C AND D)Tento vzthah platí pokud jsou všechny vyplněny. Většinou však je uváděna jedna nebo dvě kolonky a pak se logický vztah upravuje např. takto:
A AND Bnebo
A OR Cpříp.
(A AND B) OR CVždy však jde o to, že hodnota importovaná se rovná hodnotě uložené v databázi. Pokud dojde k nalezení odpovídajícího údaje, je záznam v databázi aktualizován údaji importovanými, pokud to není pomocí volby zakázat úpravu znemožněno. Pokud nalezen není, je importovaný řádek přidán jako nový dokument / záznam, opět však za předpokladu, že toto není znemožněno volbou zakázat přidávání. Můžete tak mít soubor, který naimportujete s tím, že budou importovány jen dosud neexistující záznamy nebo naopak můžete požadovat pouze upravení již zavedených údajů. Obě volby z logického hlediska zatrhnout nelze a importní proces se při nich nespustí. S párovacími schopnostmi souvisí i volba upravovat prázdné, která při zapnuté funkci párování umožňuje párovat pro doplnění údajů jen na prázdné hodnoty, tj. již nastavené alternativy při této vobě algoritmus importu ponechá.
Volba spustit při startu umožní při aktivaci nástroje (např. zástupcem přímo ze složky, kde je vstupní soubor umístěn) rovnou úlohu spustit bez dalšího klikání. Obdobnou volbu je možné najít u nástroje pro vkládání příloh. Poslední zatrhávací pole umožňuje automaticky okno nástrojů po dokončení úlohy zavřít, což vede k vyšší pracovní efektivitě v běžné praxi.
Importované, ale i dialogem dodatečně zadávané hodnoty označované identifikátorem je možné, za využití XSLT nástroje dále formátovat pro účely přípravy hodnoty pro uložení do databáze. Hodnoty, jako jsou například datumy, importní program naformátuje do potřebné podoby k uložení sám (zmíněný datum např. vyžaduje formát YYYY-MM-DD). Jsou však zvláštní aplikační požadavky nebo neobvyklé vstupní formáty dat, které vyžadují před importem ještě zvláštní úpravu. Tak například může být žádoucí, aby telefonní číslo bylo zadáváno bez mezer, lomítek a pomlček a bylo vždy doplněno plusem a předvolbou země, pokud ji již neobsahuje. Takových to možností inteligentního formátování je možné dosáhnout pomocí XSLT šablon. CSV import probíhá tím způsobem, že jednotlivé řádky vstupní CSV tabulky jsou vkládány po základním naformátování na odpovídající místo definovaného XML dokumentu v rámci požadavku na uložení dokumentů. Před vlastním uložením je pak na importem požadovaná místa (prvky dokumentu) možné uplatnit vlastní dodané xsl:template, které je třeba zapsat do souboru csv-import\temps\formats.xsl (v umístění pracovní složky nástrojů). V tomto souboru najdete již předpřipravené šablony bezMezer, bezMezerAVelkymi a zapsat, podle jejichž vzoru můžete připravit i své vlastní nebo i využít těchto přednastavených. UPOZORNĚNÍ: Vedle toho, že umístíte do zmíněného souboru kmenové tagy xsl:template s odpovídajícím atributem name, je třeba je i zavést do rozdělovníku v šabloně se jménem xDistribution stejně, jako jsou zavedené již zmíněné šablony vzorové. Indikaci použití šablony při importu dle zmíněného souboru pak v nastavení importu provedete dle syntaxe:
{#xds-id}[-{#tempName}[({#param}*)]]Můžete tak například chtít do sloupce s xds-id 10001234 chtít zapsat hodnotu 'ahoj':
10001234-zapsat(ahoj)Ze syntaxe a příkladu je patrné, že použití připravené šablony v XSLT souboru odkazujete uvedením jejího name za pomlčkou a dále ji můžete parametrizovat uvedením hodnoty v závorce. Hodnotu pak najdete v atributu f-params přímo u formátovaného segmentu a pro její získání postačí v šabloně odkaz @f-params. Příklad opět najdete v šabloně zapsat ve zmíněném souboru formats.xsl.
Tak jak je v nástojích obvyklé, je možné předdefinovat uživatelům několik běžných úloh otevíraných vhodně připravenými zástupci přímo z importních složek na straně jedné (viz. Pracovní složky a nastavení) a šablon importních tabulek pro Excel či jiný tabulkový kalkulátor na straně druhé a zajistit tak snadné vkládání externě získávaných tabulkových dat.